Library Interface
As described in the chapter about the Abstraction, the general design of the library is very similar to CUDA and OpenCL but extends both by some points, while not requiring any language extensions. General interface design as well as interface implementation decisions differentiating alpaka from those libraries are described in the Rationale section. It uses C++ because it is one of the most performant languages available on nearly all systems. Furthermore, C++20 allows to describe the concepts in a very abstract way that is not possible with many other languages. The alpaka library extensively makes use of advanced functional C++ template meta-programming techniques. The Implementation Details section discusses the C++ library and the way it provides extensibility and optimizability.
Structure
The alpaka library allows offloading of computations from the host execution domain to the accelerator execution domain, whereby they are allowed to be identical.
In the abstraction hierarchy the library code is interleaved with user supplied code as is depicted in the following figure.
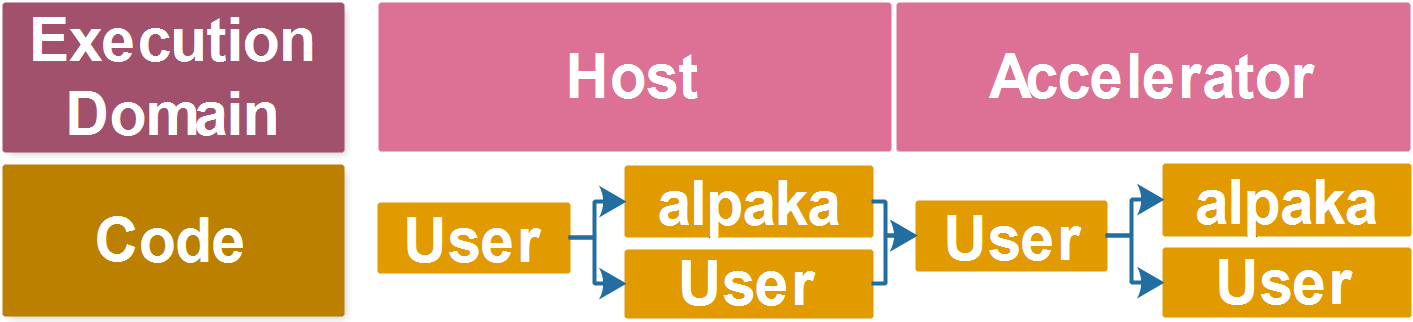
User code invokes library functions, which in turn execute the user provided thread function (kernel) in parallel on the accelerator. The kernel in turn calls library functions when accessing accelerator properties and methods. Additionally, the user can enhance or optimize the library implementations by extending or replacing specific parts.
The alpaka abstraction itself only defines requirements a type has to fulfill to be usable with the template functions the library provides. These type constraints are called concepts in C++.
A concept is a set of requirements consisting of valid expressions, associated types, invariants, and complexity guarantees. A type that satisfies the requirements is said to model the concept. A concept can extend the requirements of another concept, which is called refinement. BoostConcepts
Concepts allow to safely define polymorphic algorithms that work with objects of many different types.
The alpaka library implements a stack of concepts and their interactions modeling the abstraction defined in the previous chapter. Furthermore, default implementations for various devices and accelerators modeling those are included in the library. The interaction of the main user facing concepts can be seen in the following figure.
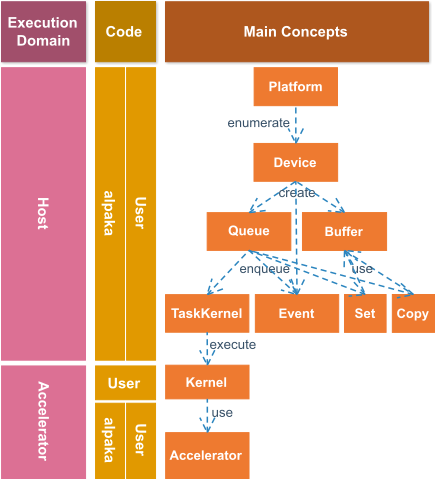
For each type of Device there is a Platform for enumerating the available Device``s.
A ``Device is the requirement for creating Queues and Events as it is for allocating Buffers on the respective Device. Buffers can be copied, their memory be set and they can be pinned or mapped.
Copying and setting a buffer requires the corresponding Copy and Set tasks to be enqueued into the Queue.
An Event can be enqueued into a Queue and its completion state can be queried by the user.
It is possible to wait for (synchronize with) a single Event, a Queue or a whole Device.
An Executor can be enqueued into a Queue and will execute the Kernel (after all previous tasks in the queue have been completed).
The Kernel in turn has access to the Accelerator it is running on.
The Accelerator provides the Kernel with its current index in the block or grid, their extents or other data as well as it allows to allocate shared memory, execute atomic operations and many more.
Interface Usage
Accelerator Functions
Functions that should be executable on an accelerator have to be annotated with the execution domain (one of ALPAKA_FN_HOST, ALPAKA_FN_ACC and ALPAKA_FN_HOST_ACC).
They most probably also require access to the accelerator data and methods, such as indices and extents as well as functions to allocate shared memory and to synchronize all threads within a block.
Therefore the accelerator has to be passed in as a templated constant reference parameter as can be seen in the following code snippet.
template<
typename TAcc>
ALPAKA_FN_ACC auto doSomethingOnAccelerator(
TAcc const & acc/*,
...*/) // Arbitrary number of parameters
-> int // Arbitrary return type
{
//...
}
Kernel Definition
A kernel is a special function object which has to conform to the following requirements:
it has to fulfill the
std::is_trivially_copyabletrait (has to be copyable via memcpy)the
operator()is the kernel entry point * it has to be an accelerator executable function * it has to returnvoid* its first argument has to be the accelerator (templated for arbitrary accelerator back-ends) * all other arguments must fulfillstd::is_trivially_copyable
The following code snippet shows a basic example of a kernel function object.
struct MyKernel
{
template<
typename TAcc> // Templated on the accelerator type.
ALPAKA_FN_ACC // Macro marking the function to be executable on all accelerators.
auto operator()( // The function / kernel to execute.
TAcc const & acc/*, // The specific accelerator implementation.
...*/) const // Must be 'const'.
-> void
{
//...
}
// Class can have members but has to be std::is_trivially_copyable.
// Classes must not have pointers or references to host memory!
};
The kernel function object is shared across all threads in all blocks.
Due to the block execution order being undefined, there is no safe and consistent way of altering state that is stored inside of the function object.
Therefore, the operator() of the kernel function object has to be const and is not allowed to modify any of the object members.
Kernels can also be defined via lambda expressions.
auto kernel = [] ALPAKA_FN_ACC (auto const & acc /* , ... */) -> void {
// ...
}
Attention
NVIDIA’s nvcc compiler does not support generic lambdas which are marked with __device__, which is what ALPAKA_FN_ACC expands to (among others) when the CUDA backend is active.
Therefore, a workaround is required. The type of the acc must be defined outside the lambda.
int main() {
// ...
using Acc = alpaka::AccGpuCudaRt<Dim, Idx>;
auto kernel = [] ALPAKA_FN_ACC (Acc const & acc /* , ... */) -> void {
// ...
}
// ...
}
However, the kernel is no longer completely generic and cannot be used with different accelerators. If this is required, the kernel must be defined as a function object.
Index and Work Division
The alpaka::getWorkDiv and the alpaka::getIdx functions both return a vector of the dimensionality the accelerator has been defined with.
They are parametrized by the origin of the calculation as well as the unit in which the values are calculated.
For example, alpaka::getWorkDiv<alpaka::Grid, alpaka::Threads>(acc) returns a vector with the extents of the grid in units of threads.
Memory fences
Note: Memory fences should not be mistaken for synchronization functions between threads. They solely enforce the
ordering of certain memory instructions (see below) and restrict how other threads can observe this order. If you need
to rely on the results of memory operations being visible to other threads you must use alpaka::syncBlockThreads or
atomic functions instead.
The alpaka::mem_fence function can be used inside an alpaka kernel to issue a memory fence instruction. This
guarantees the following for the local thread and regardless of global or shared memory:
All loads that occur before the fence will happen before all loads occurring after the fence, i.e. no LoadLoad reordering.
All stores that occur before the fence will happen before all stores occurring after the fence, i.e. no StoreStore reordering.
The order of stores will be visible to other threads inside the scope (but not necessarily their results).
Note: alpaka::mem_fence does not guarantee that there will be no LoadStore reordering. Depending on the
back-end, loads occurring before the fence may still be reordered with stores occurring after the fence.
Memory fences can be issued on the block level (alpaka::memory_scope::Block), grid level
(alpaka::memory_scope::Grid) and the device level (alpaka::memory_scope::Device).
Depending on the memory scope, the StoreStore order will be visible to other threads in the same block, in the same grid
(_i.e._ within the same kernel launch), or on the whole device (_i.e._ across concurrent kernel launches).
Some accelerators (like GPUs) follow weaker cache coherency rules than x86 CPUs. In order to avoid storing to (or loading from) a cache or register it is necessary to prefix all observed buffers with ALPAKA_DEVICE_VOLATILE. This enforces that all loads / stores access the actual global / shared memory location.
Example:
/* Initial values:
* vars[0] = 1
* vars[1] = 2
*/
template<typename TAcc>
ALPAKA_FN_ACC auto operator()(TAcc const& acc, bool* success, ALPAKA_DEVICE_VOLATILE int* vars) const -> void
{
auto const idx = alpaka::getIdx<alpaka::Grid, alpaka::Threads>(acc)[0u];
// Global thread 0 is producer
if(idx == 0)
{
vars[0] = 10;
alpaka::mem_fence(acc, alpaka::memory_scope::Device{});
vars[1] = 20;
}
auto const b = vars[1];
alpaka::mem_fence(acc, alpaka::memory_scope::Device{});
auto const a = vars[0];
/* Possible results at this point:
* a == 1 && b == 2
* a == 10 && b == 2
* a == 10 && b == 20
*
* but NOT:
* a == 1 && b == 20
*/
}
Memory Management
The memory allocation function of the alpaka library (alpaka::allocBuf<TElem>(device, extents)) is uniform for all devices, even for the host device.
It does not return raw pointers but reference counted memory buffer objects that remove the necessity for manual freeing and the possibility of memory leaks.
Additionally, the memory buffer objects know their extents, their pitches as well as the device they reside on.
Due to padding, the allocated number of bytes may be more than the required storage; the pitch value gives the correct stride for each dimension for row-major access.
This allows buffers that possibly reside on different devices with different pitches to be copied by providing the buffer objects as well as the extents of the region to copy (alpaka::memcpy(queue, bufDevA, bufDevB, copyExtents).
If the data is already in a contiguous STL container on the host; the container can be converted to a View to be used in alpaka::memcpy function. The data structure alpaka::View knows the the extent and the device of the data; therefore can be used in memcpy. (alpaka::memcpy(queue, bufDevA, viewDevB, copyExtents).
Kernel Execution
The following source code listing shows the execution of a kernel by enqueuing the execution task into a queue.
// Define the dimensionality of the task.
using Dim = alpaka::DimInt<1u>;
// Define the type of the indexes.
using Idx = std::size_t;
// Define the accelerator to use.
using Acc = alpaka::AccCpuSerial<Dim, Idx>;
// Select the queue type.
using Queue = alpaka::QueueCpuNonBlocking;
// Select a device to execute on.
auto platformAcc = alpaka::Platform<Acc>{};
auto devAcc = alpaka::getDevByIdx(platformAcc, 0);
// Create a queue to enqueue the execution into.
Queue queue(devAcc);
// Create a 1-dimensional work division with 256 blocks a 16 threads.
auto const workDiv = alpaka::WorkDivMembers<Dim, Idx>(256u, 16u);
// Create an instance of the kernel function object.
MyKernel kernel;
// Enqueue the execution task into the queue.
alpaka::exec<Acc>(queue, workDiv, kernel/*, arguments ...*/);
The dimensionality of the task as well as the type for index and extent have to be defined explicitly. Following this, the type of accelerator to execute on, as well as the type of the queue have to be defined. For both of these types instances have to be created. For the accelerator this has to be done indirectly by enumerating the required device via the device manager, whereas the queue can be created directly.
To execute the kernel, an instance of the kernel function object has to be constructed. Following this, an execution task combining the work division (grid and block sizes) with the kernel function object and the bound invocation arguments has to be created. After that this task can be enqueued into a queue for immediate or later execution (depending on the queue used).